Stephen A.I. Smith
2019-11-15This is just so DISRESPECTFUL
Sometimes a series of events comes together so nicely for a project that I just have to drop every other thing I’m doing. This week, that resulted in Stephen A.I. Smith, a model that generates Stephen A. Smith style tweets, trained using the “small” 124 million parameter version of Open AI’s state-of-the-art GPT-2. Twitter accounts like these are nothing new, but it was my *duty* to make this particular one.
I want to make it very clear that I am in no way mocking Stephen A. Smith; I consider him one of the greatest television personalities out there, and he has been (and will continue to be) a perpetual source of entertainment over the past decade. This project started out as an exercise comparing RNNs to statistical time series models, but here we are.
Here are some hand-picked tweets that were generated. I replaced ‘@’ with ‘<at>’ to avoid spamming random accounts, and links in tweets were replaced with the <url> tag for data sanitation purposes. For the full effect, try to read these in his voice:
- <at>lakethisb I don’t blame you bro. I don’t care if you’re a <at>warriors fan, or a Lakers fan, you can tell I’m watching. We don’t give a damn about <at>KyrieIrving. We’re <at>trend
- I don’t think anyone is better than <at>KyrieIrving. <url>
- I want to apologize for being completely idiotic. I’m a reporter and I’m the one with the passion. I don’t care about the words people spew. I get it. If you can’t agree, why the hell do you want to disagree.
- The <at>nyjets were so desperate to sign <at>warriors WR <at>KlayThompson to the #NFL. They told me he’d sign w/t the <at>warriors but they had no interest. And the <at>tribs have refused him
- <at>kennybluft That’s why I’ve come up with this hashtag: Haterspirit. And now I’ll be the one to tell you all that <at>RealSkipBayless is going down!
- I don’t have that many followers because I’m not trying to change, but I have enough followers. What I need is more followers.
- Golden State is doing it again Jimmer Fredette. They can’t allow Brock Osweiler to go. #WhatAEPream <url>
- There’s a reason the 49ers were stripped of <at>TigerWoods on Sunday. <url>
- I’m not buying that. This kid at Vanderbilt is so horrible, I wish he’d’ve been ejected. He deserves some money.
- <at>theRobMac I don’t. But he’s my friend. My sister. I do what I do. I’m doing WHAT I DO. I’m not defending anyone, though.
Some of the tweets are very coherent, others are complete junk, and quite a few are entertaining. Even though the GPT-2 model should produce good generated text, re-training on the twitter data introduces noise, since tweets typically contain poor spelling/grammar, and unknown tokens such as emojis and hashtags (not to mention the cornucopia of equivocal words that is Stephen A’s lexicon).
Another feature of the model is sentence completion, where you can input leading sentences and have the model finish the tweet. For example, leading with “The best player in the NBA is”, we get:
- The best player in the NBA is Dwight Howard #NBAPlayoffs <url>
- The best player in the NBA is the one we love.#Enlightenment <url>
- The best player in the NBA is a future history teacher??? I know this. If Teague is there, there will be a class action suit later.
- The best player in the NBA is AJ Green. You don’t LIE to the world!” Similarly said, Thanks my man!
- The best player in the NBA is Lance Stephenson. Only time will tell if he can … <at>KingJames eventually shifted from the L.A. media to NY rather than LA. <url>
Leading with “The Lakers should trade”:
- The Lakers should trade Kobe, too, but if they’re going to be a contender they have to find a way to draft well. They do not have a clear No.1 with Melo. It won’t matter.
- The Lakers should trade Kobe Bryant to Nashville, Draymond. I’m just saying Jeff Van Gundy has to be careful to not make his Kobe-hating end too ugly, too soon. No wonder MSG just stares! <url>
- The Lakers should trade KG. Kobe is 32 years old and they’re still in the West. Besides, Pau Gasol is better. Nobody wants to see KG with Kobe, but you can sure as hell do a deal that’ll leave him outside the West.
- The Lakers should trade Ndamukong Suh for Roy Williams. From: Jon Gruden <url>
- The Lakers should trade Kobe Bryant. The Lakers should trade Kobe if the offer is in the range of the 4th-tier teams. Knicks should fail in front of a TV crowd again. Example for anyone who wants to learn how to do that, follow the tweets. The Lakers should be greedy over Bryant and get this done. After 9 Years of Bowing out on salary, Paulie would lead Lakers to MEGA LEAGUE win. That’s all
Leading with “Drake is without a doubt”:
- Drake is without a doubt stronger, he has the demeanor to be *more* emotional and He knows how to handle it. Effort is skill. Period.
- Drake is without a doubt the HONORABLE MAN. Anyone who dares disrespect him, I am giving you VERY BAD DETAILS.
- Drake is without a doubt the best Editor in the game. Cortana is wasting her time and Eloquence by downplaying what <url>e on our Bowl Subdivision Title fives. We’re WAY INITIALLY TO the NFL playoffs. We’re a+
- Drake is without a doubt the best big man in the world..not getting the opportunity to go against him every night. As for Kevin Love…HAVE FUN. He’s still a top-6 player via data. STupid PRACTICAL SENSE is what I believe in. Better men can become great NBA players than dumb ones.
- Drake is without a doubt the greatest receiver to ever lace it up. Seems like he’s doing that quite a bit more. And he’s not holding back on the smell. I’m loving this.
Who is Stephen A. Smith?
This is not the first time Stephen A. Smith has been the subject of applied machine learning, but it is shocking that a Google search of “Stephen A. Smith text generator” yielded no similar projects. The man is an icon in the sports television community. He has about 100 jobs, most notably as the co-host of ESPN’s First Take, and is perhaps best known for his hilarious catchphrases, his insightful commentary, and his starring role on ABC’s General Hospital. If you have the right sense of humor, a few clips is all it takes to appreciate him. Here is a collection of some of his greatest hits (I take no responsibility for any changes to your YouTube recommendations):
- Asi-nine, asi-ten, asi-eleven, asi-twelve
- Blasphemous
- Disrespectful
- Hoodwinked, bamboozled, led astray, run amok, and FLAT OUT DECEIVED
- JaMarcus Russell
- Kwame Brown (example 1), Kwame Brown (example 2: Bill Walton with the lob)
- Slava & Rasho
- The temerity, the unmitigated gall…
How are the tweets generated?
Due to the prohibitive size of the released GPT-2 models, it was difficult to have a streamlined end-to-end process on my local machine (let alone my tiny t2.micro AWS EC2 instance), as even the smallest model is not easily re-trainable on my 1080 Ti. As a result, the process is a bit more nuanced, as illustrated below.
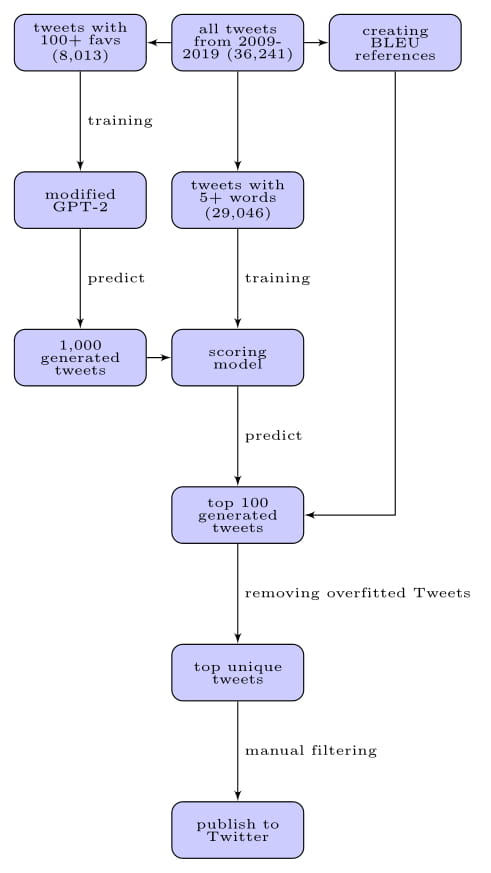
Tweets are scraped using a modified version of this repo. Since Stephen A has many short tweets like “thanks” or “appreciate it” or “haa”, I filtered for the most popular tweets (100 or more favs), so that I can re-train the GPT-2 model on his greatest hits. The training itself is facilitated by this useful wrapper and the use of a Google Colab notebook. Once the model is done re-training, I can use it to generate new tweets, or to complete leading prompts. I typically generate 1,000 tweets at a time.
Of course, it would be very time-consuming to manually sort through the sea of output, so I built a separate scoring model (using essentially all the scraped Tweets) to classify tweets with 100+ favs. The generated tweets are fed through this scoring model, and I keep the top 100 to manually review. Finally, to remove any overfitted predictions, I compute the BLEU score of each of the 100 tweets (using the original tweets as reference), and filter out tweets who are too similar to existing tweets.
This project really made me appreciate the open source community; 10 years ago, doing a comparable project would have taken me months due to the need to code and learn each major step from scratch. To try it out yourself, the GPT-2 training data I used can be found here, and you can use the re-training template in this Colab notebook by Max Woolf.
Additional technical details
- The BLEU score takes a very long time to compute because the reference group I am using is over 36,000 tweets; in this analogy, the candidate tweet is compared to over 36,000 ‘valid translations’. There was little evidence of overfitting, so I typically skip this step. As a result, some tweets may indeed be similar to existing tweets (this could also happen by chance as well).
- The scoring model uses a Bidirectional LSTM. This achieved an estimated AUC (for both PR and ROC) of over 0.9, which is way way way more than enough for this particular use case. I used a pre-trained embedding layer via the GloVe Twitter vectors.
- The predicted probabilities of the scoring model are left skewed. This actually makes sense because the GPT-2 model is trained on tweets with 100+ favs, while the scoring model is trained on all tweets. This data sharing is not ideal, but is reasonably inconsequential for this exercise.
- I tried a handful of architectures before stumbling across GPT-2. A lot of the time, those simpler models would either overfit (generating tweets too similar to the training data), or generate too much nonsense. With additional tweaking, the performance of the simpler models would improve, but I gave up on that after finding GPT-2.
- The whole repo can be found here. A large master list of the generated tweets can be found here, but be aware that there will be offensive content in there. I am posting these to demonstrate the capabilities of the GPT-2 model.